
Implementing observability in cloud-native applications
Implementing observability in cloud-native applications Cloud-native hosting technologies have taken centre stage ever since they were…

Implementing observability in cloud-native applications Cloud-native hosting technologies have taken centre stage ever since they were…

Software mapping is an important concept in the field of software engineering and cloud computing. It…

Duncan is an award-winning researcher, with 20 years experience of analysing the technology industry, specialising in…

Introduction In the digital age, the ability to effectively manage time and tasks is invaluable, especially…
In an interview with CloudTweaks, Frank Kim, a SANS Fellow and cloud security expert, discusses the…
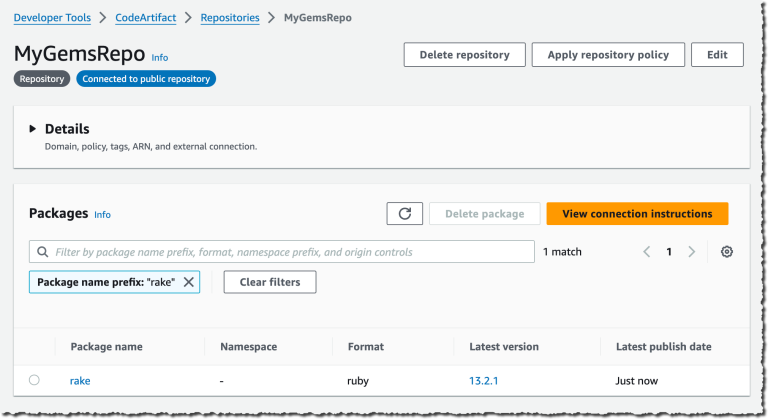
Ruby developers can now use AWS CodeArtifact to securely store and retrieve their gems. CodeArtifact integrates…

What is Matrix? Matrix is an open protocol for decentralized, secure communications built on the principles…

The Internet has a plethora of moving parts: routers, switches, hubs, terrestrial and submarine cables, and…
So Fedora Workstation 40 Beta has just come out so I thought I share a bit…

We are happy to announce that coming in Q3 of 2024, with the release of cPanel…
With the year slowly coming to an end, we draw the curtains on yet another chapter…
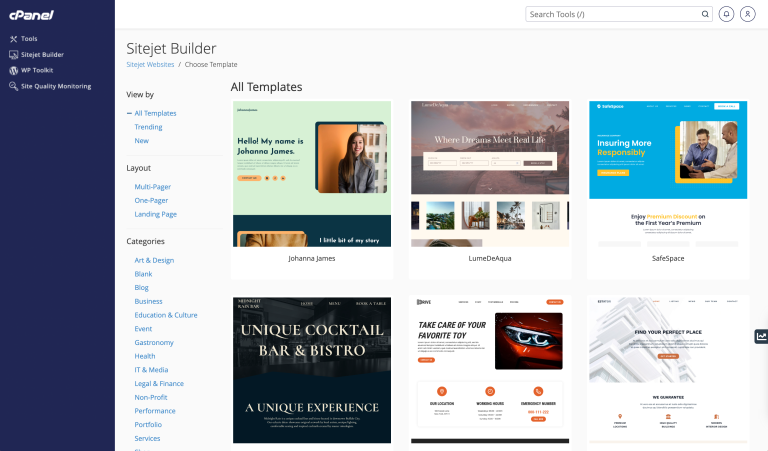
We are excited to start the year off strong by sharing some exciting news: both Sitejet…
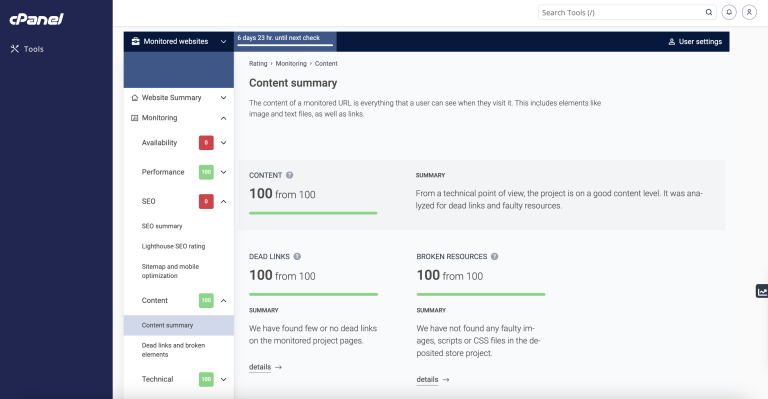
Site Quality Monitoring (SQM) for cPanel is now available with cPanel’s v118, v116, and v110 LTS…
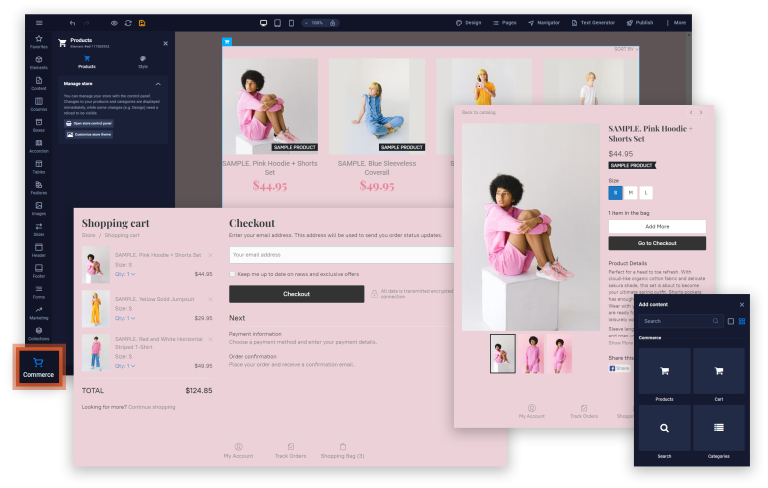
Great news! Are you looking to add an online store to your Sitejet-driven website? With Sitejet…
About the Author By James Bourne | 19th March 2024 https://www.cloudcomputing-news.net/ Categories: Applications, AWS, Cloud Computing,…
In an ever-evolving digital landscape, the cloud has emerged as a ubiquitous storage and processing platform…

Starting today, administrators of package repositories can manage the configuration of multiple packages in one single…